AliCloud Releases Qwen 2 Open Source Model which the Performance Beats All Current Open Source Models and Domestic Closed Source Models
Overview

Alibaba Cloud has unveiled its groundbreaking Qwen 2 open-source large language model (LLM), surpassing all existing open-source and domestic closed-source models in terms of performance. Qwen 2 boasts a comprehensive range of capabilities, including exceptional natural language processing (NLP) abilities, robust coding and mathematical skills, and impressive multilingual proficiency.

Key Features
- Model Sizes: Qwen 2 encompasses a diverse range of model sizes, catering to varied needs and applications. These include:
- Qwen2–0.5B: Ideal for resource-constrained devices and tasks with low computational demands
- Qwen2–1.5B: Suitable for medium-scale tasks requiring greater complexity than Qwen2–0.5B
- Qwen2–7B: A mid-large model well-suited for tasks demanding robust language processing capabilities
- Qwen2–57B-A14B: A large-scale model designed for tasks requiring high performance and precision
- Qwen2–72B: The series’ largest model, tailored for handling highly complex tasks and extensive datasets

- GQA Technology: All Qwen 2 models leverage Generalized Query Attention (GQA) technology, significantly boosting inference speed and reducing memory consumption.
- Context Length: Qwen 2 models are trained on a massive 32K-token dataset, enabling them to process lengthy texts effectively. Additionally, they demonstrate remarkable performance when handling 128K-token contexts.
- Instruction-Fine-Tuned Models: Qwen 2 offers a suite of instruction-fine-tuned models specifically optimized for particular tasks. These include Qwen2–7B-Instruct and Qwen2–72B-Instruct, capable of processing contexts reaching 128K tokens.
- Multilingual Capabilities: Qwen 2 models are optimized for 27 languages, exhibiting significant enhancements in multilingual processing, particularly beyond Chinese and English.
- Shared Parameter Technique: Smaller models employ tie embedding technology, sharing parameters between input and output layers, increasing non-embedding parameter占比, enhancing model performance within the same size constraints.

Benchmark Results
Qwen 2 models have consistently outperformed their counterparts in various benchmarks, showcasing exceptional performance across a wide spectrum of tasks. Notable highlights include:
- Natural Language Processing: Qwen2–72B surpasses current leading open-source models, including Llama-3–70B and Qwen1.5–110B, in natural language understanding, knowledge mastery, code generation, mathematical capabilities, and multilingual processing.
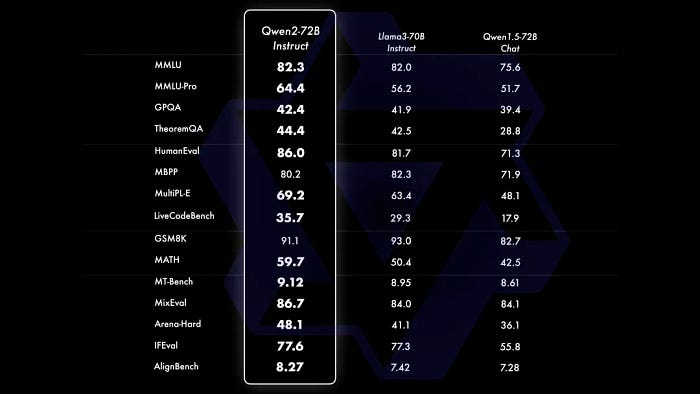
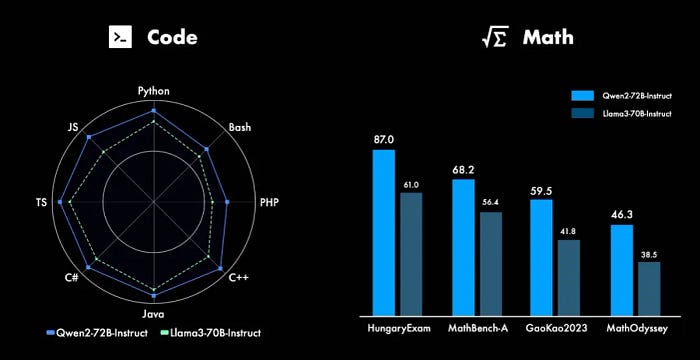
- Coding and Mathematical Skills: Qwen 2 models exhibit remarkable proficiency in various programming languages, particularly excelling in code generation and comprehension tasks. Qwen2–72B-Instruct, trained on a vast dataset of high-quality mathematical data, demonstrates exceptional problem-solving abilities.
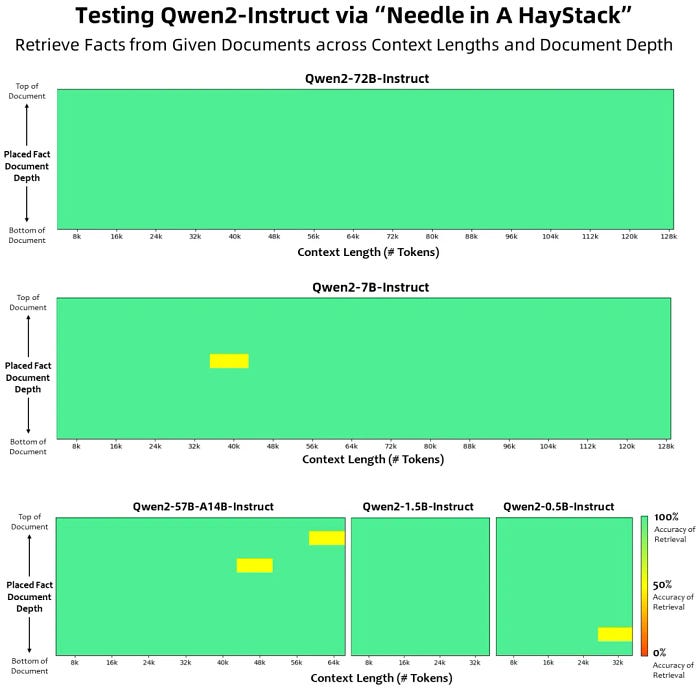
- Long Text Processing: Qwen 2 models excel in handling long texts. All Instruct models are trained on 32K-token contexts and can be extended to even longer lengths using techniques like YARN or Dual Chunk Attention. Qwen2–72B-Instruct demonstrates consistent performance on contexts reaching 128K tokens, while Qwen2–7B-Instruct and Qwen2–57B-A14B-Instruct can effectively process 128K and 64K tokens, respectively.
- Multilingual Processing: Qwen 2 models showcase outstanding multilingual capabilities, particularly in 27 languages beyond Chinese and English. Language switching instances are significantly reduced, enabling smoother handling of multilingual content.
- Safety: Qwen2–72B-Instruct matches GPT-4’s performance in handling multilingual unsafe queries, including illegal activities, fraud, pornography, and privacy violations. It outperforms Mixtral-8x22B by a considerable margin. Evaluated using data from Jailbreak and translated into multiple languages, Qwen 2 models demonstrate robust safety measures.
Detailed Benchmark Results
- Natural Language Understanding: Qwen2–72B excels in natural language understanding benchmarks, surpassing other leading models like Llama-3–70B.
- Knowledge Mastery: In knowledge assessment tasks, Qwen2–72B demonstrates remarkable proficiency in answering complex questions.
- Code Generation: Qwen 2 models shine in code generation tasks, particularly in multilingual programming environments.
- Mathematical Capabilities: Qwen2–72B-Instruct exhibits exceptional mathematical problem-solving abilities due to its training on a vast dataset of high-quality mathematical data.
- Multilingual Processing: Optimized for 27 languages, Qwen 2 models exhibit reduced language switching and enhanced overall multilingual handling.
- Long Text Processing: Qwen2–72B-Instruct and other models consistently perform well on long text tasks, effectively processing extended contexts.
Availability
Qwen 2 models are readily available as open-source on Hugging Face and ModelScope. Please refer to the respective model cards for detailed usage instructions.
Download: https://modelscope.cn/organization/qwen
Github: https://github.com/QwenLM/Qwen2
Try online: https://huggingface.co/spaces/Qwen/Qwen2-72B-Instruct
Official: https://qwenlm.github.io/blog/qwen2/

